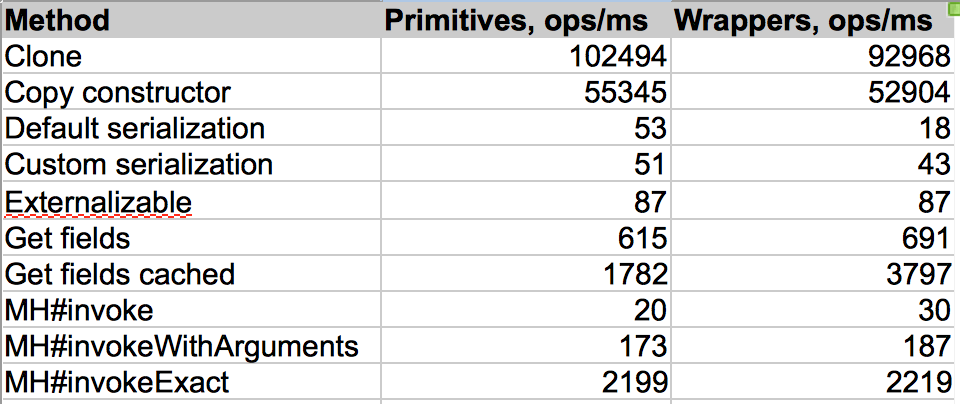
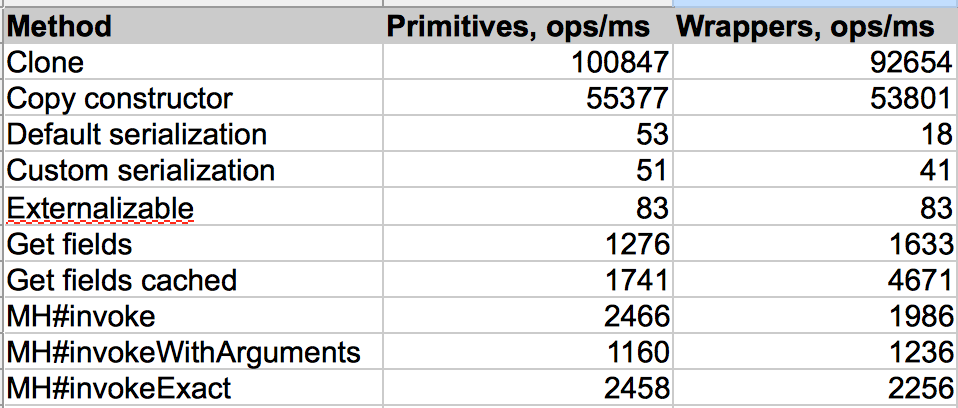
This post is a followup on my previous post about copying objects in Java. After I published that post I got a question from Sven Reimers (@SvenNB) why there is a big performance different between clone and copying via constructor. In this post I will try to answer this question.
Code in question
Just to recap what we are looking at. There are 2 classes implementing copy() method:
- Copy via
clone():
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
package com.vyazelenko.blog.copyobject.primitives.clone; import com.vyazelenko.blog.copyobject.primitives.BaseClass; public class CloneCopy extends BaseClass implements Cloneable { public static final CloneCopy INSTANCE; static { INSTANCE = new CloneCopy(); INSTANCE.init(); } @Override protected CloneCopy clone() { try { return (CloneCopy) super.clone(); } catch (CloneNotSupportedException e) { throw new Error(e); } } @Override public CloneCopy copy() { return clone(); } } - Copy via constructor:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
package com.vyazelenko.blog.copyobject.primitives.constructor; import com.vyazelenko.blog.copyobject.primitives.BaseClass; public class ConstructorCopy extends BaseClass implements Cloneable { public static final ConstructorCopy INSTANCE; static { INSTANCE = new ConstructorCopy(); INSTANCE.init(); } public ConstructorCopy() { super(); } public ConstructorCopy(ConstructorCopy copyFrom) { super(copyFrom); } @Override public ConstructorCopy copy() { return new ConstructorCopy(this); } }
Both of these classes inherit from the common base class that defines state to be copied:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| package com.vyazelenko.blog.copyobject.primitives; | |
| import com.vyazelenko.blog.copyobject.Copyable; | |
| import com.vyazelenko.blog.copyobject.HashUtils; | |
| abstract class Root implements Copyable { | |
| private int field1; | |
| private char field2; | |
| public boolean field6; | |
| byte abc; | |
| public long min; | |
| public long max; | |
| private double maxExponent; | |
| public Root() { | |
| } | |
| public void init() { | |
| field1 = 100; | |
| field2 = '\t'; | |
| field6 = false; | |
| abc = -100; | |
| min = Long.MIN_VALUE; | |
| max = Long.MAX_VALUE; | |
| maxExponent = Double.MAX_VALUE; | |
| } | |
| public Root(Root copyFrom) { | |
| field1 = copyFrom.field1; | |
| field2 = copyFrom.field2; | |
| field6 = copyFrom.field6; | |
| abc = copyFrom.abc; | |
| min = copyFrom.min; | |
| max = copyFrom.max; | |
| maxExponent = copyFrom.maxExponent; | |
| } | |
| @Override | |
| public boolean equals(Object obj) { | |
| if (obj == this) { | |
| return true; | |
| } else if (!(obj instanceof Root)) { | |
| return false; | |
| } else { | |
| Root tmp = (Root) obj; | |
| return field1 == tmp.field1 && field2 == tmp.field2 && field6 == tmp.field6 | |
| && abc == tmp.abc && min == tmp.min && max == tmp.max | |
| && Double.compare(maxExponent, tmp.maxExponent) == 0; | |
| } | |
| } | |
| @Override | |
| public int hashCode() { | |
| int hash = 17; | |
| hash += 31 * hash + field1; | |
| hash += 31 * hash + field2; | |
| hash += 31 * hash + (field6 ? 1 : 0); | |
| hash += 31 * hash + abc; | |
| hash += 31 * hash + HashUtils.longHash(min); | |
| hash += 31 * hash + HashUtils.longHash(max); | |
| hash += 31 * hash + HashUtils.doubleHash(maxExponent); | |
| return hash; | |
| } | |
| } | |
| public abstract class BaseClass extends Root { | |
| private double anotherField; | |
| private int field1; | |
| protected long youCanSeeMe; | |
| private short m1; | |
| public short m2; | |
| public short m3; | |
| public short m4; | |
| short m5; | |
| public short m6; | |
| public short m7; | |
| protected short m8; | |
| public short m9; | |
| public short m10; | |
| private char x; | |
| public BaseClass() { | |
| super(); | |
| } | |
| @Override | |
| public void init() { | |
| super.init(); | |
| anotherField = 10.5; | |
| field1 = Integer.MIN_VALUE; | |
| youCanSeeMe = -1; | |
| m1 = 10; | |
| m2 = 20; | |
| m3 = 30; | |
| m4 = 40; | |
| m5 = 50; | |
| m6 = 60; | |
| m7 = 70; | |
| m8 = 80; | |
| m9 = 90; | |
| m10 = 100; | |
| x = '\n'; | |
| } | |
| public BaseClass(BaseClass copyFrom) { | |
| super(copyFrom); | |
| anotherField = copyFrom.anotherField; | |
| field1 = copyFrom.field1; | |
| youCanSeeMe = copyFrom.youCanSeeMe; | |
| m1 = copyFrom.m1; | |
| m2 = copyFrom.m2; | |
| m3 = copyFrom.m3; | |
| m4 = copyFrom.m4; | |
| m5 = copyFrom.m5; | |
| m6 = copyFrom.m6; | |
| m7 = copyFrom.m7; | |
| m8 = copyFrom.m8; | |
| m9 = copyFrom.m9; | |
| m10 = copyFrom.m10; | |
| x = copyFrom.x; | |
| } | |
| @Override | |
| public boolean equals(Object obj) { | |
| if (obj == this) { | |
| return true; | |
| } else if (!(obj instanceof BaseClass)) { | |
| return false; | |
| } else { | |
| BaseClass tmp = (BaseClass) obj; | |
| return super.equals(tmp) && Double.compare(anotherField, tmp.anotherField) == 0 | |
| && field1 == tmp.field1 && youCanSeeMe == tmp.youCanSeeMe | |
| && m1 == tmp.m1 && m2 == tmp.m2 && m3 == tmp.m3 && m4 == tmp.m4 | |
| && m5 == tmp.m5 && m6 == tmp.m6 && m7 == tmp.m7 && m8 == tmp.m8 | |
| && m9 == tmp.m9 && m10 == tmp.m10 && x == tmp.x; | |
| } | |
| } | |
| @Override | |
| public int hashCode() { | |
| int hash = super.hashCode(); | |
| hash = 31 * hash + HashUtils.doubleHash(anotherField); | |
| hash = 31 * hash + field1; | |
| hash = 31 * hash + HashUtils.longHash(youCanSeeMe); | |
| hash = 31 * hash + m1; | |
| hash = 31 * hash + m2; | |
| hash = 31 * hash + m3; | |
| hash = 31 * hash + m4; | |
| hash = 31 * hash + m5; | |
| hash = 31 * hash + m6; | |
| hash = 31 * hash + m7; | |
| hash = 31 * hash + m8; | |
| hash = 31 * hash + m9; | |
| hash = 31 * hash + m10; | |
| hash = 31 * hash + x; | |
| return hash; | |
| } | |
| } |
Clone under the hood
java.lang.Object defines clone() method as native thus giving JVM possibility to use intrinsics. And in fact this is what OpenJDK JVM implementation is doing under the hood:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| /* | |
| * Defined in the hotspot/src/share/vm/classfile/vmSymbols.hpp | |
| */ | |
| #define VM_SYMBOLS_DO(template, do_alias) \ | |
| /* commonly used class names */ \ | |
| template(java_lang_System, "java/lang/System") \ | |
| template(java_lang_Object, "java/lang/Object") \ | |
| … | |
| #define VM_INTRINSICS_DO(do_intrinsic, do_class, do_name, do_signature, do_alias) \ | |
| do_intrinsic(_hashCode, java_lang_Object, hashCode_name, void_int_signature, F_R) \ | |
| do_name( hashCode_name, "hashCode") \ | |
| do_intrinsic(_getClass, java_lang_Object, getClass_name, void_class_signature, F_R) \ | |
| do_name( getClass_name, "getClass") \ | |
| do_intrinsic(_clone, java_lang_Object, clone_name, void_object_signature, F_R) \ | |
| do_name( clone_name, "clone") \ | |
| … |
Unfortunately I was not able to find exactly how such intrinsified clone() method call would look like. If any of you knows the answer I would be more than happy to hear about it!
Test code and results
This time I won’t be using JMH running my tests, because I just need to force JVM to compile methods in question. For each case there is a dedicated test class (i.e. TestClone.java and TestConstructor.java) that invokes copy() method 500 000 times during warmup phase and then another 10 000 000 during actual test phase. These numbers are not particularly relevant and they were chosen to ensure that JVM will compile copy methods into native code.
I will use 1.7.0_45 JDK version.
Here are test classes:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| package com.vyazelenko.blog.copyobject; | |
| import com.vyazelenko.blog.copyobject.primitives.clone.CloneCopy; | |
| import java.util.ArrayList; | |
| import java.util.List; | |
| public class TestClone { | |
| public static List<Copyable> results; | |
| public static void main(String[] args) { | |
| runTest(); | |
| } | |
| public static void runTest() { | |
| warmup(); | |
| test(); | |
| } | |
| private static void warmup() { | |
| doCopy(500_000, "warmup"); | |
| } | |
| private static void doCopy(int iterations, String message) { | |
| results = new ArrayList<>(iterations); | |
| System.out.println("\n\n>>> In " + message); | |
| for (int i = 0; i < iterations; i++) { | |
| results.add(callCopy()); | |
| } | |
| System.out.println("<<< " + message + " completed"); | |
| } | |
| private int resultsHash() { | |
| return results.hashCode(); | |
| } | |
| private static Copyable callCopy() { | |
| return CloneCopy.INSTANCE.copy(); | |
| } | |
| private static void test() { | |
| doCopy(10_000_000, "test"); | |
| } | |
| } |
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| package com.vyazelenko.blog.copyobject; | |
| import com.vyazelenko.blog.copyobject.primitives.clone.CloneCopy; | |
| import com.vyazelenko.blog.copyobject.primitives.constructor.ConstructorCopy; | |
| import java.util.ArrayList; | |
| import java.util.List; | |
| public class TestConstructor { | |
| public static List<Copyable> results; | |
| public static void main(String[] args) { | |
| runTest(); | |
| } | |
| public static void runTest() { | |
| warmup(); | |
| test(); | |
| } | |
| private static void warmup() { | |
| doCopy(500_000, "warmup"); | |
| } | |
| private static void doCopy(int iterations, String message) { | |
| results = new ArrayList<>(iterations); | |
| System.out.println("\n\n>>> In " + message); | |
| for (int i = 0; i < iterations; i++) { | |
| results.add(callCopy()); | |
| } | |
| System.out.println("<<< " + message + " completed"); | |
| } | |
| private int resultsHash() { | |
| return results.hashCode(); | |
| } | |
| private static Copyable callCopy() { | |
| return ConstructorCopy.INSTANCE.copy(); | |
| } | |
| private static void test() { | |
| doCopy(10_000_000, "test"); | |
| } | |
| } |
I ran both tests with -XX:+PrintCompilation option and got the following results:
- Clone:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
java -XX:+PrintCompilation com.vyazelenko.blog.copyobject.TestClone 59 1 java.lang.String::hashCode (55 bytes) 61 2 java.lang.String::indexOf (70 bytes) 69 3 sun.nio.cs.UTF_8$Encoder::encode (361 bytes) 77 4 java.util.ArrayList::add (29 bytes) 77 5 java.util.ArrayList::ensureCapacityInternal (23 bytes) 77 7 n java.lang.Object::clone (native) 78 6 java.util.ArrayList::ensureExplicitCapacity (26 bytes) 78 8 com.vyazelenko.blog.copyobject.TestClone::callCopy (7 bytes) 78 9 com.vyazelenko.blog.copyobject.primitives.clone.CloneCopy::copy (5 bytes) 79 10 ! com.vyazelenko.blog.copyobject.primitives.clone.CloneCopy::clone (18 bytes) 79 11 % com.vyazelenko.blog.copyobject.TestClone::doCopy @ 38 (92 bytes) 105 12 com.vyazelenko.blog.copyobject.TestClone::doCopy (92 bytes) - Constructor:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
java -XX:+PrintCompilation com.vyazelenko.blog.copyobject.TestConstructor 59 1 java.lang.String::hashCode (55 bytes) 61 2 java.lang.String::indexOf (70 bytes) 70 3 sun.nio.cs.UTF_8$Encoder::encode (361 bytes) 77 4 java.lang.Object::<init> (1 bytes) 80 5 java.util.ArrayList::add (29 bytes) 80 6 java.util.ArrayList::ensureCapacityInternal (23 bytes) 81 7 java.util.ArrayList::ensureExplicitCapacity (26 bytes) 81 8 com.vyazelenko.blog.copyobject.TestConstructor::callCopy (7 bytes) 81 9 com.vyazelenko.blog.copyobject.primitives.constructor.ConstructorCopy::copy (9 bytes) 83 10 com.vyazelenko.blog.copyobject.primitives.constructor.ConstructorCopy::<init> (6 bytes) 83 11 com.vyazelenko.blog.copyobject.primitives.BaseClass::<init> (118 bytes) 83 12 com.vyazelenko.blog.copyobject.primitives.Root::<init> (61 bytes) 83 13 % com.vyazelenko.blog.copyobject.TestConstructor::doCopy @ 38 (92 bytes) 113 14 com.vyazelenko.blog.copyobject.TestConstructor::doCopy (92 bytes)
This by itself is not telling us much except that in the second (constructor) case there are 2 more entries that were compiled (i.e. BaseClass::<init> and Root::<init>).
The real fun is to look into generated assembler code (i.e. -XX:+UnlockDiagnosticVMOptions -XX:+PrintAssembly). If you want to know how to dump assembly you can use java-print-assembly instructions provided by Nitsan Wakart on his blog. Links to proper binaries saved me tons of time today. 😉
I will show here only relevant part of the assembly dumps which contain only compiled callCopy() method from each test class, because it is the one we are interested in:
- Clone (complete ASM code):
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Decoding compiled method 0x00000001063b9390: Code: [Entry Point] [Verified Entry Point] [Constants] # {method} 'callCopy' '()Lcom/vyazelenko/blog/copyobject/Copyable;' in 'com/vyazelenko/blog/copyobject/TestClone' # [sp+0x20] (sp of caller) 0x00000001063b94e0: mov %eax,-0x14000(%rsp) 0x00000001063b94e7: push %rbp 0x00000001063b94e8: sub $0x10,%rsp 0x00000001063b94ec: mov 0x60(%r15),%rsi 0x00000001063b94f0: mov %rsi,%r10 0x00000001063b94f3: add $0x58,%r10 0x00000001063b94f7: cmp 0x70(%r15),%r10 0x00000001063b94fb: jae 0x00000001063b9557 0x00000001063b94fd: mov %r10,0x60(%r15) 0x00000001063b9501: prefetchnta 0xc0(%r10) 0x00000001063b9509: mov $0xd7610ea1,%r11d ; {oop('com/vyazelenko/blog/copyobject/primitives/clone/CloneCopy')} 0x00000001063b950f: mov 0xb0(%r12,%r11,8),%r10 0x00000001063b9517: mov %r10,(%rsi) 0x00000001063b951a: movl $0xd7610ea1,0x8(%rsi) ; {oop('com/vyazelenko/blog/copyobject/primitives/clone/CloneCopy')} 0x00000001063b9521: mov %rsi,%rbx 0x00000001063b9524: add $0x8,%rsi 0x00000001063b9528: mov $0xa,%edx 0x00000001063b952d: movabs $0x7957a9d90,%rdi ; {oop(a 'com/vyazelenko/blog/copyobject/primitives/clone/CloneCopy')} 0x00000001063b9537: add $0x8,%rdi 0x00000001063b953b: movabs $0x106398120,%r10 0x00000001063b9545: callq *%r10 ;*invokespecial clone ; – com.vyazelenko.blog.copyobject.primitives.clone.CloneCopy::clone@1 (line 16) ; – com.vyazelenko.blog.copyobject.primitives.clone.CloneCopy::copy@1 (line 24) ; – com.vyazelenko.blog.copyobject.TestClone::callCopy@3 (line 38) 0x00000001063b9548: mov %rbx,%rax 0x00000001063b954b: add $0x10,%rsp 0x00000001063b954f: pop %rbp 0x00000001063b9550: test %eax,-0x1bcc556(%rip) # 0x00000001047ed000 ; {poll_return} 0x00000001063b9556: retq 0x00000001063b9557: movabs $0x6bb087508,%rsi ; {oop('com/vyazelenko/blog/copyobject/primitives/clone/CloneCopy')} 0x00000001063b9561: xchg %ax,%ax 0x00000001063b9563: callq 0x00000001063b4fe0 ; OopMap{off=136} ;*invokespecial clone ; – com.vyazelenko.blog.copyobject.primitives.clone.CloneCopy::clone@1 (line 16) ; – com.vyazelenko.blog.copyobject.primitives.clone.CloneCopy::copy@1 (line 24) ; – com.vyazelenko.blog.copyobject.TestClone::callCopy@3 (line 38) ; {runtime_call} 0x00000001063b9568: mov %rax,%rsi 0x00000001063b956b: jmp 0x00000001063b9521 0x00000001063b956d: mov 0x8(%rax),%r10d 0x00000001063b9571: cmp $0xd7610fdb,%r10d ; {oop('java/lang/CloneNotSupportedException')} 0x00000001063b9578: je 0x00000001063b9587 0x00000001063b957a: mov %rax,%rsi 0x00000001063b957d: add $0x10,%rsp 0x00000001063b9581: pop %rbp 0x00000001063b9582: jmpq 0x00000001063b7e20 ; {runtime_call} 0x00000001063b9587: mov %rax,%rbp ;*areturn ; – com.vyazelenko.blog.copyobject.primitives.clone.CloneCopy::clone@7 (line 16) ; – com.vyazelenko.blog.copyobject.primitives.clone.CloneCopy::copy@1 (line 24) ; – com.vyazelenko.blog.copyobject.TestClone::callCopy@3 (line 38) 0x00000001063b958a: mov $0x5,%esi 0x00000001063b958f: callq 0x000000010638ef20 ; OopMap{rbp=Oop off=180} ;*new ; – com.vyazelenko.blog.copyobject.primitives.clone.CloneCopy::clone@9 (line 18) ; – com.vyazelenko.blog.copyobject.primitives.clone.CloneCopy::copy@1 (line 24) ; – com.vyazelenko.blog.copyobject.TestClone::callCopy@3 (line 38) ; {runtime_call} 0x00000001063b9594: callq 0x0000000105c165de ;*new ; – com.vyazelenko.blog.copyobject.primitives.clone.CloneCopy::clone@9 (line 18) ; – com.vyazelenko.blog.copyobject.primitives.clone.CloneCopy::copy@1 (line 24) ; – com.vyazelenko.blog.copyobject.TestClone::callCopy@3 (line 38) ; {runtime_call} 0x00000001063b9599: hlt 0x00000001063b959a: hlt 0x00000001063b959b: hlt 0x00000001063b959c: hlt 0x00000001063b959d: hlt 0x00000001063b959e: hlt 0x00000001063b959f: hlt [Exception Handler] [Stub Code] 0x00000001063b95a0: jmpq 0x00000001063b50a0 ; {no_reloc} [Deopt Handler Code] 0x00000001063b95a5: callq 0x00000001063b95aa 0x00000001063b95aa: subq $0x5,(%rsp) 0x00000001063b95af: jmpq 0x000000010638eb00 ; {runtime_call} 0x00000001063b95b4: hlt 0x00000001063b95b5: hlt 0x00000001063b95b6: hlt 0x00000001063b95b7: hlt - Constructor (complete ASM code):
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Decoding compiled method 0x000000010c064b50: Code: [Entry Point] [Verified Entry Point] [Constants] # {method} 'callCopy' '()Lcom/vyazelenko/blog/copyobject/Copyable;' in 'com/vyazelenko/blog/copyobject/TestConstructor' # [sp+0x20] (sp of caller) 0x000000010c064ca0: mov %eax,-0x14000(%rsp) 0x000000010c064ca7: push %rbp 0x000000010c064ca8: sub $0x10,%rsp ;*synchronization entry ; – com.vyazelenko.blog.copyobject.TestConstructor::callCopy@-1 (line 39) 0x000000010c064cac: mov 0x60(%r15),%r8 0x000000010c064cb0: mov %r8,%r10 0x000000010c064cb3: add $0x58,%r10 0x000000010c064cb7: cmp 0x70(%r15),%r10 0x000000010c064cbb: jae 0x000000010c064de3 0x000000010c064cc1: mov %r10,0x60(%r15) 0x000000010c064cc5: prefetchnta 0xc0(%r10) 0x000000010c064ccd: mov %r8,%rdi 0x000000010c064cd0: add $0x10,%rdi 0x000000010c064cd4: mov $0xd7610e71,%r10d ; {oop('com/vyazelenko/blog/copyobject/primitives/constructor/ConstructorCopy')} 0x000000010c064cda: mov 0xb0(%r12,%r10,8),%r10 0x000000010c064ce2: mov %r10,(%r8) 0x000000010c064ce5: movl $0xd7610e71,0x8(%r8) ; {oop('com/vyazelenko/blog/copyobject/primitives/constructor/ConstructorCopy')} 0x000000010c064ced: mov %r12d,0xc(%r8) 0x000000010c064cf1: mov $0x9,%ecx 0x000000010c064cf6: xor %rax,%rax 0x000000010c064cf9: shl $0x3,%rcx 0x000000010c064cfd: rep rex.W stos %al,%es:(%rdi) ;*new ; – com.vyazelenko.blog.copyobject.primitives.constructor.ConstructorCopy::copy@0 (line 23) ; – com.vyazelenko.blog.copyobject.TestConstructor::callCopy@3 (line 39) 0x000000010c064d00: mov %r8,%rax ;*areturn ; – com.vyazelenko.blog.copyobject.TestConstructor::callCopy@6 (line 39) 0x000000010c064d03: movabs $0x7957aa098,%r9 ; {oop(a 'com/vyazelenko/blog/copyobject/primitives/constructor/ConstructorCopy')} 0x000000010c064d0d: mov 0xc(%r9),%r11d 0x000000010c064d11: mov %r11d,0xc(%r8) ;*putfield field1 ; – com.vyazelenko.blog.copyobject.primitives.Root::<init>@9 (line 29) ; – com.vyazelenko.blog.copyobject.primitives.BaseClass::<init>@2 (line 106) ; – com.vyazelenko.blog.copyobject.primitives.constructor.ConstructorCopy::<init>@2 (line 18) ; – com.vyazelenko.blog.copyobject.primitives.constructor.ConstructorCopy::copy@5 (line 23) ; – com.vyazelenko.blog.copyobject.TestConstructor::callCopy@3 (line 39) 0x000000010c064d15: movzwl 0x54(%r9),%r10d 0x000000010c064d1a: mov %r10w,0x54(%r8) ;*putfield x ; – com.vyazelenko.blog.copyobject.primitives.BaseClass::<init>@114 (line 120) ; – com.vyazelenko.blog.copyobject.primitives.constructor.ConstructorCopy::<init>@2 (line 18) ; – com.vyazelenko.blog.copyobject.primitives.constructor.ConstructorCopy::copy@5 (line 23) ; – com.vyazelenko.blog.copyobject.TestConstructor::callCopy@3 (line 39) 0x000000010c064d1f: movswl 0x52(%r9),%r11d 0x000000010c064d24: mov %r11w,0x52(%r8) ;*putfield m10 ; – com.vyazelenko.blog.copyobject.primitives.BaseClass::<init>@106 (line 119) ; – com.vyazelenko.blog.copyobject.primitives.constructor.ConstructorCopy::<init>@2 (line 18) ; – com.vyazelenko.blog.copyobject.primitives.constructor.ConstructorCopy::copy@5 (line 23) ; – com.vyazelenko.blog.copyobject.TestConstructor::callCopy@3 (line 39) 0x000000010c064d29: movswl 0x50(%r9),%r10d 0x000000010c064d2e: mov %r10w,0x50(%r8) ;*putfield m9 ; – com.vyazelenko.blog.copyobject.primitives.BaseClass::<init>@98 (line 118) ; – com.vyazelenko.blog.copyobject.primitives.constructor.ConstructorCopy::<init>@2 (line 18) ; – com.vyazelenko.blog.copyobject.primitives.constructor.ConstructorCopy::copy@5 (line 23) ; – com.vyazelenko.blog.copyobject.TestConstructor::callCopy@3 (line 39) 0x000000010c064d33: movswl 0x4e(%r9),%r11d 0x000000010c064d38: mov %r11w,0x4e(%r8) ;*putfield m8 ; – com.vyazelenko.blog.copyobject.primitives.BaseClass::<init>@90 (line 117) ; – com.vyazelenko.blog.copyobject.primitives.constructor.ConstructorCopy::<init>@2 (line 18) ; – com.vyazelenko.blog.copyobject.primitives.constructor.ConstructorCopy::copy@5 (line 23) ; – com.vyazelenko.blog.copyobject.TestConstructor::callCopy@3 (line 39) 0x000000010c064d3d: movswl 0x4c(%r9),%r10d 0x000000010c064d42: mov %r10w,0x4c(%r8) ;*putfield m7 ; – com.vyazelenko.blog.copyobject.primitives.BaseClass::<init>@82 (line 116) ; – com.vyazelenko.blog.copyobject.primitives.constructor.ConstructorCopy::<init>@2 (line 18) ; – com.vyazelenko.blog.copyobject.primitives.constructor.ConstructorCopy::copy@5 (line 23) ; – com.vyazelenko.blog.copyobject.TestConstructor::callCopy@3 (line 39) 0x000000010c064d47: movswl 0x4a(%r9),%r11d 0x000000010c064d4c: mov %r11w,0x4a(%r8) ;*putfield m6 ; – com.vyazelenko.blog.copyobject.primitives.BaseClass::<init>@74 (line 115) ; – com.vyazelenko.blog.copyobject.primitives.constructor.ConstructorCopy::<init>@2 (line 18) ; – com.vyazelenko.blog.copyobject.primitives.constructor.ConstructorCopy::copy@5 (line 23) ; – com.vyazelenko.blog.copyobject.TestConstructor::callCopy@3 (line 39) 0x000000010c064d51: movswl 0x48(%r9),%r10d 0x000000010c064d56: mov %r10w,0x48(%r8) ;*putfield m5 ; – com.vyazelenko.blog.copyobject.primitives.BaseClass::<init>@66 (line 114) ; – com.vyazelenko.blog.copyobject.primitives.constructor.ConstructorCopy::<init>@2 (line 18) ; – com.vyazelenko.blog.copyobject.primitives.constructor.ConstructorCopy::copy@5 (line 23) ; – com.vyazelenko.blog.copyobject.TestConstructor::callCopy@3 (line 39) 0x000000010c064d5b: movswl 0x46(%r9),%r11d 0x000000010c064d60: mov %r11w,0x46(%r8) ;*putfield m4 ; – com.vyazelenko.blog.copyobject.primitives.BaseClass::<init>@58 (line 113) ; – com.vyazelenko.blog.copyobject.primitives.constructor.ConstructorCopy::<init>@2 (line 18) ; – com.vyazelenko.blog.copyobject.primitives.constructor.ConstructorCopy::copy@5 (line 23) ; – com.vyazelenko.blog.copyobject.TestConstructor::callCopy@3 (line 39) 0x000000010c064d65: movswl 0x44(%r9),%r10d 0x000000010c064d6a: mov %r10w,0x44(%r8) ;*putfield m3 ; – com.vyazelenko.blog.copyobject.primitives.BaseClass::<init>@50 (line 112) ; – com.vyazelenko.blog.copyobject.primitives.constructor.ConstructorCopy::<init>@2 (line 18) ; – com.vyazelenko.blog.copyobject.primitives.constructor.ConstructorCopy::copy@5 (line 23) ; – com.vyazelenko.blog.copyobject.TestConstructor::callCopy@3 (line 39) 0x000000010c064d6f: movswl 0x42(%r9),%r11d 0x000000010c064d74: mov %r11w,0x42(%r8) ;*putfield m2 ; – com.vyazelenko.blog.copyobject.primitives.BaseClass::<init>@42 (line 111) ; – com.vyazelenko.blog.copyobject.primitives.constructor.ConstructorCopy::<init>@2 (line 18) ; – com.vyazelenko.blog.copyobject.primitives.constructor.ConstructorCopy::copy@5 (line 23) ; – com.vyazelenko.blog.copyobject.TestConstructor::callCopy@3 (line 39) 0x000000010c064d79: movswl 0x40(%r9),%r10d 0x000000010c064d7e: mov %r10w,0x40(%r8) ;*putfield m1 ; – com.vyazelenko.blog.copyobject.primitives.BaseClass::<init>@34 (line 110) ; – com.vyazelenko.blog.copyobject.primitives.constructor.ConstructorCopy::<init>@2 (line 18) ; – com.vyazelenko.blog.copyobject.primitives.constructor.ConstructorCopy::copy@5 (line 23) ; – com.vyazelenko.blog.copyobject.TestConstructor::callCopy@3 (line 39) 0x000000010c064d83: mov 0x38(%r9),%r10 0x000000010c064d87: mov %r10,0x38(%r8) ;*putfield youCanSeeMe ; – com.vyazelenko.blog.copyobject.primitives.BaseClass::<init>@26 (line 109) ; – com.vyazelenko.blog.copyobject.primitives.constructor.ConstructorCopy::<init>@2 (line 18) ; – com.vyazelenko.blog.copyobject.primitives.constructor.ConstructorCopy::copy@5 (line 23) ; – com.vyazelenko.blog.copyobject.TestConstructor::callCopy@3 (line 39) 0x000000010c064d8b: vmovsd 0x30(%r9),%xmm0 0x000000010c064d91: vmovsd %xmm0,0x30(%r8) ;*putfield anotherField ; – com.vyazelenko.blog.copyobject.primitives.BaseClass::<init>@10 (line 107) ; – com.vyazelenko.blog.copyobject.primitives.constructor.ConstructorCopy::<init>@2 (line 18) ; – com.vyazelenko.blog.copyobject.primitives.constructor.ConstructorCopy::copy@5 (line 23) ; – com.vyazelenko.blog.copyobject.TestConstructor::callCopy@3 (line 39) 0x000000010c064d97: mov 0x2c(%r9),%r11d 0x000000010c064d9b: mov %r11d,0x2c(%r8) ;*putfield field1 ; – com.vyazelenko.blog.copyobject.primitives.BaseClass::<init>@18 (line 108) ; – com.vyazelenko.blog.copyobject.primitives.constructor.ConstructorCopy::<init>@2 (line 18) ; – com.vyazelenko.blog.copyobject.primitives.constructor.ConstructorCopy::copy@5 (line 23) ; – com.vyazelenko.blog.copyobject.TestConstructor::callCopy@3 (line 39) 0x000000010c064d9f: movsbl 0x2b(%r9),%r10d 0x000000010c064da4: mov %r10b,0x2b(%r8) ;*putfield abc ; – com.vyazelenko.blog.copyobject.primitives.Root::<init>@33 (line 32) ; – com.vyazelenko.blog.copyobject.primitives.BaseClass::<init>@2 (line 106) ; – com.vyazelenko.blog.copyobject.primitives.constructor.ConstructorCopy::<init>@2 (line 18) ; – com.vyazelenko.blog.copyobject.primitives.constructor.ConstructorCopy::copy@5 (line 23) ; – com.vyazelenko.blog.copyobject.TestConstructor::callCopy@3 (line 39) 0x000000010c064da8: movzbl 0x2a(%r9),%r11d 0x000000010c064dad: mov %r11b,0x2a(%r8) ;*putfield field6 ; – com.vyazelenko.blog.copyobject.primitives.Root::<init>@25 (line 31) ; – com.vyazelenko.blog.copyobject.primitives.BaseClass::<init>@2 (line 106) ; – com.vyazelenko.blog.copyobject.primitives.constructor.ConstructorCopy::<init>@2 (line 18) ; – com.vyazelenko.blog.copyobject.primitives.constructor.ConstructorCopy::copy@5 (line 23) ; – com.vyazelenko.blog.copyobject.TestConstructor::callCopy@3 (line 39) 0x000000010c064db1: movzwl 0x28(%r9),%r10d 0x000000010c064db6: mov %r10w,0x28(%r8) ;*putfield field2 ; – com.vyazelenko.blog.copyobject.primitives.Root::<init>@17 (line 30) ; – com.vyazelenko.blog.copyobject.primitives.BaseClass::<init>@2 (line 106) ; – com.vyazelenko.blog.copyobject.primitives.constructor.ConstructorCopy::<init>@2 (line 18) ; – com.vyazelenko.blog.copyobject.primitives.constructor.ConstructorCopy::copy@5 (line 23) ; – com.vyazelenko.blog.copyobject.TestConstructor::callCopy@3 (line 39) 0x000000010c064dbb: vmovsd 0x20(%r9),%xmm0 0x000000010c064dc1: vmovsd %xmm0,0x20(%r8) ;*putfield maxExponent ; – com.vyazelenko.blog.copyobject.primitives.Root::<init>@57 (line 35) ; – com.vyazelenko.blog.copyobject.primitives.BaseClass::<init>@2 (line 106) ; – com.vyazelenko.blog.copyobject.primitives.constructor.ConstructorCopy::<init>@2 (line 18) ; – com.vyazelenko.blog.copyobject.primitives.constructor.ConstructorCopy::copy@5 (line 23) ; – com.vyazelenko.blog.copyobject.TestConstructor::callCopy@3 (line 39) 0x000000010c064dc7: mov 0x18(%r9),%r10 0x000000010c064dcb: mov %r10,0x18(%r8) ;*putfield max ; – com.vyazelenko.blog.copyobject.primitives.Root::<init>@49 (line 34) ; – com.vyazelenko.blog.copyobject.primitives.BaseClass::<init>@2 (line 106) ; – com.vyazelenko.blog.copyobject.primitives.constructor.ConstructorCopy::<init>@2 (line 18) ; – com.vyazelenko.blog.copyobject.primitives.constructor.ConstructorCopy::copy@5 (line 23) ; – com.vyazelenko.blog.copyobject.TestConstructor::callCopy@3 (line 39) 0x000000010c064dcf: mov 0x10(%r9),%r10 0x000000010c064dd3: mov %r10,0x10(%r8) ;*putfield min ; – com.vyazelenko.blog.copyobject.primitives.Root::<init>@41 (line 33) ; – com.vyazelenko.blog.copyobject.primitives.BaseClass::<init>@2 (line 106) ; – com.vyazelenko.blog.copyobject.primitives.constructor.ConstructorCopy::<init>@2 (line 18) ; – com.vyazelenko.blog.copyobject.primitives.constructor.ConstructorCopy::copy@5 (line 23) ; – com.vyazelenko.blog.copyobject.TestConstructor::callCopy@3 (line 39) 0x000000010c064dd7: add $0x10,%rsp 0x000000010c064ddb: pop %rbp 0x000000010c064ddc: test %eax,-0x10b4de2(%rip) # 0x000000010afb0000 ; {poll_return} 0x000000010c064de2: retq 0x000000010c064de3: movabs $0x6bb087388,%rsi ; {oop('com/vyazelenko/blog/copyobject/primitives/constructor/ConstructorCopy')} 0x000000010c064ded: xchg %ax,%ax 0x000000010c064def: callq 0x000000010c05efe0 ; OopMap{off=340} ;*new ; – com.vyazelenko.blog.copyobject.primitives.constructor.ConstructorCopy::copy@0 (line 23) ; – com.vyazelenko.blog.copyobject.TestConstructor::callCopy@3 (line 39) ; {runtime_call} 0x000000010c064df4: mov %rax,%r8 0x000000010c064df7: jmpq 0x000000010c064d00 ;*new ; – com.vyazelenko.blog.copyobject.primitives.constructor.ConstructorCopy::copy@0 (line 23) ; – com.vyazelenko.blog.copyobject.TestConstructor::callCopy@3 (line 39) 0x000000010c064dfc: mov %rax,%rsi 0x000000010c064dff: add $0x10,%rsp 0x000000010c064e03: pop %rbp 0x000000010c064e04: jmpq 0x000000010c061e20 ; {runtime_call} 0x000000010c064e09: hlt 0x000000010c064e0a: hlt 0x000000010c064e0b: hlt 0x000000010c064e0c: hlt 0x000000010c064e0d: hlt 0x000000010c064e0e: hlt 0x000000010c064e0f: hlt 0x000000010c064e10: hlt 0x000000010c064e11: hlt 0x000000010c064e12: hlt 0x000000010c064e13: hlt 0x000000010c064e14: hlt 0x000000010c064e15: hlt 0x000000010c064e16: hlt 0x000000010c064e17: hlt 0x000000010c064e18: hlt 0x000000010c064e19: hlt 0x000000010c064e1a: hlt 0x000000010c064e1b: hlt 0x000000010c064e1c: hlt 0x000000010c064e1d: hlt 0x000000010c064e1e: hlt 0x000000010c064e1f: hlt [Exception Handler] [Stub Code] 0x000000010c064e20: jmpq 0x000000010c05f0a0 ; {no_reloc} [Deopt Handler Code] 0x000000010c064e25: callq 0x000000010c064e2a 0x000000010c064e2a: subq $0x5,(%rsp) 0x000000010c064e2f: jmpq 0x000000010c038b00 ; {runtime_call} 0x000000010c064e34: hlt 0x000000010c064e35: hlt 0x000000010c064e36: hlt 0x000000010c064e37: hlt
As you can see clone case has much shorter assembler code and basically it is just an *invokespecial clone invocation. Whereas in the constructor case we see much bigger assembler output and in essence it contains multiple *putfield invocations.
CPU counters
Eventually I managed to compile Intel Performance Counter Monitor 2.5.1 on my OS X 10.9.
Here are the results of running clone and constructor code under PCM (NB: I changed number of iterations to 20'000'000 in test() method for this run):
- Clone:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
pcm.x "java -Xms4g -Xmx5g com.vyazelenko.blog.copyobject.TestClone" -nc -ns Intel(r) Performance Counter Monitor V2.5.1 (2013-06-25 13:44:03 +0200 ID=76b6d1f) Copyright (c) 2009-2012 Intel Corporation Num logical cores: 8 Num sockets: 1 Threads per core: 2 Core PMU (perfmon) version: 3 Number of core PMU generic (programmable) counters: 4 Width of generic (programmable) counters: 48 bits Number of core PMU fixed counters: 3 Width of fixed counters: 48 bits Nominal core frequency: 2700000000 Hz Package thermal spec power: 45 Watt; Package minimum power: 36 Watt; Package maximum power: 0 Watt; Detected Intel(R) Core(TM) i7-3820QM CPU @ 2.70GHz "Intel(r) microarchitecture codename Ivy Bridge" Executing "java -Xms4g -Xmx5g com.vyazelenko.blog.copyobject.TestClone" command: … EXEC : instructions per nominal CPU cycle IPC : instructions per CPU cycle FREQ : relation to nominal CPU frequency='unhalted clock ticks'/'invariant timer ticks' (includes Intel Turbo Boost) AFREQ : relation to nominal CPU frequency while in active state (not in power-saving C state)='unhalted clock ticks'/'invariant timer ticks while in C0-state' (includes Intel Turbo Boost) L3MISS: L3 cache misses L2MISS: L2 cache misses (including other core's L2 cache *hits*) L3HIT : L3 cache hit ratio (0.00-1.00) L2HIT : L2 cache hit ratio (0.00-1.00) L3CLK : ratio of CPU cycles lost due to L3 cache misses (0.00-1.00), in some cases could be >1.0 due to a higher memory latency L2CLK : ratio of CPU cycles lost due to missing L2 cache but still hitting L3 cache (0.00-1.00) READ : bytes read from memory controller (in GBytes) WRITE : bytes written to memory controller (in GBytes) TEMP : Temperature reading in 1 degree Celsius relative to the TjMax temperature (thermal headroom): 0 corresponds to the max temperature Core (SKT) | EXEC | IPC | FREQ | AFREQ | L3MISS | L2MISS | L3HIT | L2HIT | L3CLK | L2CLK | READ | WRITE | TEMP ——————————————————————————————————————- TOTAL * 0.39 0.65 0.60 1.30 51 M 67 M 0.23 0.30 0.57 0.05 N/A N/A N/A Instructions retired: 10 G ; Active cycles: 16 G ; Time (TSC): 3425 Mticks ; C0 (active,non-halted) core residency: 46.24 % C1 core residency: 11.19 %; C3 core residency: 0.01 %; C6 core residency: 0.00 %; C7 core residency: 42.57 % C2 package residency: 0.00 %; C3 package residency: 0.00 %; C6 package residency: 0.00 %; C7 package residency: 0.00 % PHYSICAL CORE IPC : 1.29 => corresponds to 32.32 % utilization for cores in active state Instructions per nominal CPU cycle: 0.78 => corresponds to 19.43 % core utilization over time interval ———————————————————————————————- - Constructor:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
"java -Xms4g -Xmx5g com.vyazelenko.blog.copyobject.TestConstructor" -nc -ns Intel(r) Performance Counter Monitor V2.5.1 (2013-06-25 13:44:03 +0200 ID=76b6d1f) Copyright (c) 2009-2012 Intel Corporation Num logical cores: 8 Num sockets: 1 Threads per core: 2 Core PMU (perfmon) version: 3 Number of core PMU generic (programmable) counters: 4 Width of generic (programmable) counters: 48 bits Number of core PMU fixed counters: 3 Width of fixed counters: 48 bits Nominal core frequency: 2700000000 Hz Package thermal spec power: 45 Watt; Package minimum power: 36 Watt; Package maximum power: 0 Watt; Detected Intel(R) Core(TM) i7-3820QM CPU @ 2.70GHz "Intel(r) microarchitecture codename Ivy Bridge" Executing "java -Xms4g -Xmx5g com.vyazelenko.blog.copyobject.TestConstructor" command: … EXEC : instructions per nominal CPU cycle IPC : instructions per CPU cycle FREQ : relation to nominal CPU frequency='unhalted clock ticks'/'invariant timer ticks' (includes Intel Turbo Boost) AFREQ : relation to nominal CPU frequency while in active state (not in power-saving C state)='unhalted clock ticks'/'invariant timer ticks while in C0-state' (includes Intel Turbo Boost) L3MISS: L3 cache misses L2MISS: L2 cache misses (including other core's L2 cache *hits*) L3HIT : L3 cache hit ratio (0.00-1.00) L2HIT : L2 cache hit ratio (0.00-1.00) L3CLK : ratio of CPU cycles lost due to L3 cache misses (0.00-1.00), in some cases could be >1.0 due to a higher memory latency L2CLK : ratio of CPU cycles lost due to missing L2 cache but still hitting L3 cache (0.00-1.00) READ : bytes read from memory controller (in GBytes) WRITE : bytes written to memory controller (in GBytes) TEMP : Temperature reading in 1 degree Celsius relative to the TjMax temperature (thermal headroom): 0 corresponds to the max temperature Core (SKT) | EXEC | IPC | FREQ | AFREQ | L3MISS | L2MISS | L3HIT | L2HIT | L3CLK | L2CLK | READ | WRITE | TEMP ——————————————————————————————————————- TOTAL * 0.35 0.64 0.55 1.31 51 M 68 M 0.26 0.29 0.53 0.06 N/A N/A N/A Instructions retired: 11 G ; Active cycles: 17 G ; Time (TSC): 3988 Mticks ; C0 (active,non-halted) core residency: 41.93 % C1 core residency: 11.82 %; C3 core residency: 0.00 %; C6 core residency: 0.00 %; C7 core residency: 46.25 % C2 package residency: 0.00 %; C3 package residency: 0.00 %; C6 package residency: 0.00 %; C7 package residency: 0.00 % PHYSICAL CORE IPC : 1.27 => corresponds to 31.76 % utilization for cores in active state Instructions per nominal CPU cycle: 0.70 => corresponds to 17.38 % core utilization over time interval ———————————————————————————————-
What this output shows is that clone case is faster because amount of instructions executed is lower, i.e. there is less code to execute:
- TestClone:
Instructions retired: 10 G ; Active cycles: 16 G ; Time (TSC): 3425 Mticks
- TestConstructor:
Instructions retired: 11 G ; Active cycles: 17 G ; Time (TSC): 3988 Mticks